简介: 本文将介绍分贝通在大数据领域的一些建设经验。分贝通在ToB领域是一个年轻的公司,成立六年多,大数据体系刚刚建立一年多,整个团队不到二十人,整体的大数据建设处于初级和摸索的阶段。本次将总结在大数据业务上的实践和思考,希望给大家带来启发。
分享嘉宾:吴荣彬 分贝通 大数据部负责人
导读:本文将介绍分贝通在大数据领域的一些建设经验。分贝通在ToB领域是一个年轻的公司,成立六年多,大数据体系刚刚建立一年多,整个团队不到二十人,整体的大数据建设处于初级和摸索的阶段。本次将总结在大数据业务上的实践和思考,希望给大家带来启发。
主要内容包括以下几方面:
公司介绍
大数据建设背景
大数据建设方案
大数据应用场景
公司介绍
先简单介绍一下分贝通。
我们平常公司中可能会遇到这种场景,比如出差时通过公司OA或邮件进行审批,然后去订机票、火车票、酒店等,到了目的地之后很多费用还要自己垫付,回来再通过发票报销,发票数量多且金额大,时间耗费多;同时对公司而言,因为要对接很多外部平台,对企业和员工而言都是非常麻烦的。

分贝通致力于解决企业这方面的痛点,除了差旅这部分大的支出,我们也希望在所有的支出管理场景提供整体解决方案,实现企业在预算、审批、交易、报销的全流程闭环。对员工而言,所有支出都在一个平台,可以不用垫资和发票,使用非常便捷。对企业而言,可以做到事前预算管理,事中费用控制,事后自动报销,极大的减轻了财务和行政的工作量。
前提是分贝通需要提前去对接不同的供应商,比如酒店供应商、用车供应商等。在某些场景,分贝通还在建立自己的供应商体系,包括自营的酒店、自营的商城。经过六年多的发展,该模式得到了投资人和市场的认可,现在服务于数千家客户,业务增长迅速,融资的规模也比较可观,目前在企业服务领域算是独角兽的存在。
大数据建设背景
我们公司的大数据部门去年才成立,之前整个公司数据底层建设比较匮乏,所有数据都是通过业务研发团队去支撑,业务研发除了很多自己的产品功能迭代以外,还要排期去做数据支持。整体体验较差,一个业务上线需要一到两个月。这可能是所有ToB公司必经的一个阶段,ToB公司一开始的数据量可能不是特别大,不像ToC公司一开始就有自己的大数据团队,随着ToB公司的发展,数据量变大后,对大数据团队建设的需求是非常迫切的。

这是我们去年业务部门的需求,可以看到整个团队在底层数据方面的需求处于井喷的状态,未来可能有更多更细的需求。
对于一个ToB公司来说,基本上可以把客户旅程分为六个阶段:认知、教育、选择、支付、使用、增购。这是我们基于硅谷蓝图的SaaS获客模型优化后的划分,对整个国内ToB行业也有参考意义。认知:当我们想谈一个客户,首先要让客户了解分贝通。我们通过广告或者电销团队去做一个初步的接触,这个叫做认知。教育:当有一定需求,客户想起分贝通这个公司,会联系你做深度的交流和拜访,这时是深度教育的阶段,让客户了解我们能够解决他的什么问题。选择:通过多家的对比选择了分贝通。使用:交付使用。增购:发现有一些其他功能还不错增加购买,或者到了使用年限后继续购买。
分贝通整体可以归为三类部门,第一是业务部门,包括销售、渠道、市场、客户成功等;第二是运产部门,即运营+产品的业务研发部门,包括商城、商旅、费控、支付;第三是职能部门,包括产研、人力、财务。这三大部门对数据的需求不太一样,对各个阶段的需求也会有区别。
业务部门对数据的需求是非常强烈的。其中一个场景是客户签约,客户购买了很多应用场景的模块,有些模块用得很好,有些模块用得很差,客户成功团队希望知道哪些应用场景重点在用,哪些开通了也不用,还有哪些用户在流失等等,这些都是对数据的需求。
运产部门对数据的核心要求在整个业务过程中存在卡点,希望我们通过数据去告诉它。
对于职能部门,产研关心的是产品上线后是否有人在用,用的怎样,是否能做ABtest。人力关心的是现在的员工关注的点是哪些,是薪酬还是福利。财务关注的是现在的财务报表,数据的准确性如何,跟流水是否对得上,需要很明确的被告知,以上这些都是公司对数据的需求,各种各样且非常强烈。

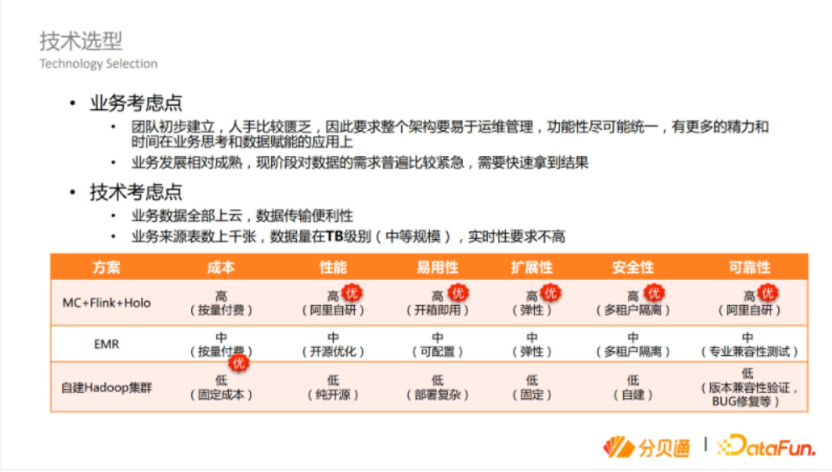
基于以上业务背景,我们需要选择合适的技术来满足业务的需求,从业务和技术两个角度来考虑。首先,从业务方面考虑,当时团队刚刚组建,人手比较匮乏,创业公司对人才的吸引力有限,因此我们的架构的应用成本要特别低,功能尽量简单,这样才能更多地进行业务思考和数据赋能。同时,由于业务已经发展到一定阶段了,对数据的需求已经比较迫切了,因此我们要快速的拿到结果。另外,从技术上考虑,原有技术数据已经上云,因此我们必须选择云端的解决方案,这样有利于数据的传输。同时,我们有很多的数据来源表,但是数据量还比较小,数据量在TB规模,对实时的要求没有那么高。
在不考虑自建IDC的前提下,当时摆在我们面前有三个选择:第一个是比较成熟的云端的组建,阿里的MaxCompute+Hologres+实时计算Flink版+大数据开发治理平台DataWork,第二个是云上开源的组建EMR,第三个是什么都不用,在云上自建Hadoop集群。这三个方案各有优缺点,第一个方案的好处是应用成本嫁接给阿里云,但应用成本较高。第二个方案是比较折中的方案,有一定的灵活性,但是在运维上也需要一定的专业性。第三个方案需要招聘非常专业的应用团队来组建自己的Hadoop集群,这在当时来看不太可行。最后综合来看,我们选择了方案一。
大数据建设方案
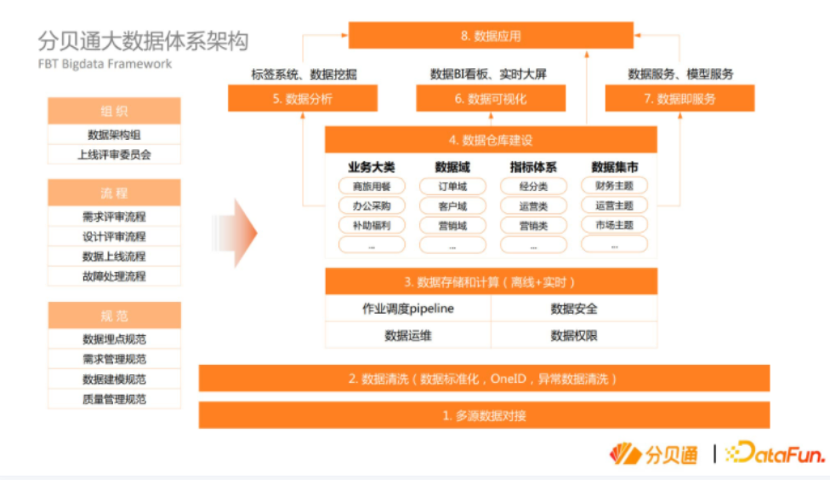
技术架构选型结束后,我们开始从内部梳理大数据建设的整体体系,逐步进行大数据建设。与大多数大数据体系架构类似,底层是多源数据连接,往上做数据清洗,再往上进行离线和实时的数据存储与计算,到数据仓库的建设,再到上面的应用层的建设,左边是组织流程规范的一些保障。
其中一些实践方面的细节和总结值得分享。比如数据分析,对于ToB的公司来说是很大的一个模块,这里的数据分析是指对外的数据分析,希望对现有的数据进行深入的分析。在组织架构上我们将数仓和数据分析分成两个团队,数仓团队负责整个ODS和DWD层的建设,数据分析团队负责上层的DWS层和ADS层的建设,这是横向的切分。这样做的好处是,数仓团队可以更好地关注底层数据的质量,需要更多地跟研发打交道,数据分析团队只需要对数据分析负责,而数据分析师可以更加关注整个数据的应用和业务的应用。这两个团队有着完全不一样的技能,而且可以互相监督。除此之外,实时和离线不分开的好处是对于大家的技术发展而言,技术栈比较完整。
在流程和规范方面,我们当时面临的挑战是内部的业务线特别多,有十几个业务线,不仅多,并且复杂,比如用车业务线,与滴滴的业务线相似。每个业务线的表很多,每个业务之间又是独立开发的,规范需要统一,数据质量也有很大差异,是非常棘手的问题。但是同时我们也有先发优势——从零开始建设,所以我们当时确定一个原则,一定要边建设边治理而不是先建设后治理。我们摸索出了一套从业务需求到开发到上线的标准的动作,也就是所谓的SOP。比如将每周二、每周四作为固定的评审时间,评审的内容都是按照自己的内容自己的模板准备好,每次评审都有记录,上线的时候根据评审记录来看它是否完成是否需要修改,保证流程规范治理好。
一件事情做到60分是很简单的,比如数仓的建立比较简单,但是要做到极致,真正做出一个好的数仓,90分的数仓其实是一件很难的事情。
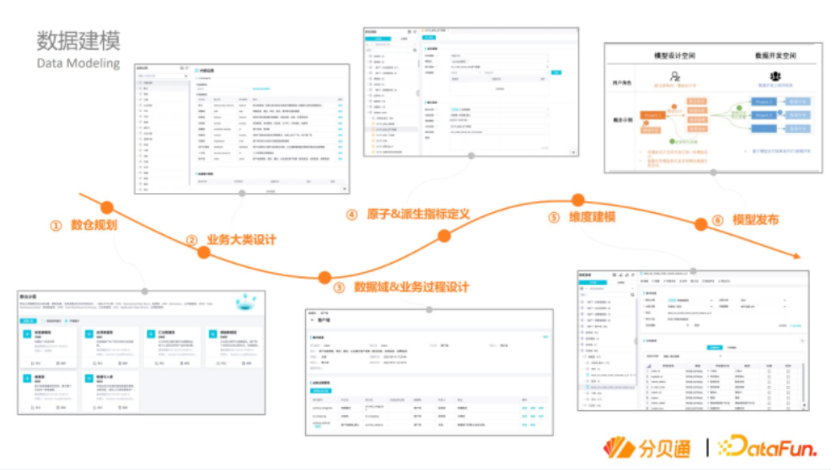
有了对于大数据整体体系的流程与思路以后,落地就需要工具的支持,下面介绍一下数据建模的工具。现在我们用的是阿里云的DataWorks智能数据建模,我们去年底参加了他们的公测,今年开始正式使用。DataWorks智能数据建模最大的好处是,我们会把整个数仓的规划和最终模型的产出做一个强关联,模型可以直接生成物理表,发布成功后也可以直接生成简单的ETL代码。之前我们在应用开发环境之前用SQL去建模,结果大家之间的标准不统一,就是一个人治的过程。有了DataWorks以后我们就变成了法治,通过工具实现了对整个数据的强治理,与原来相比,我们建模的便利性可能会差一些,比如想建一个数据汇总表,首先要建一个原始指标才能建立派生指标,然后搭建表模型,再关联数据标准,这个流程相对而言会变长,刚开始的时候大家会不太习惯。虽然单个点的流程变长,但是整体效率提升了,数仓团队都非常接受这种规范。对数据仓库的长期建设而言,一些标准与规范的事前投入是非常有必要的,往往可以起到事半功倍的效果。
上图是数仓整体架构。在技术架构方面,现在仍然是非常典型的一个lambda架构,离线与实时是分开的,结果在Hologres做了一层汇聚,有用到一些辅助的数据库如MySQL和ES来存储业务和标签的数据。这里有一些基于我们业务场景的使用建议,数据应用链Hologres与MaxCompute有离线实时一体化的能力,Hologres存在两种表存储的方法,一个是数据不导出,直接加载MaxCompute表作为外表,一个是数据导入Hologres成为内表。我们BI报表的业务场景是对外的,对我们来说是非常重要的,数据的稳定性是需要首要保证的,所以我们更多地采用Hologres内表方式去访问ODS的数据而不是外表方式,这样做的好处是一旦不小心将表的结果变更,如果是外表,BI工具只有在客户访问的时候才暴露出这种问题,但是采用内表的方式在推数的时候就会发现问题,就可以避免线下稳定性的问题。另外,我们每天都需要数据更新,我们不是每天都更新整个Hologres里面的表数据,因为这样效率会比较低,可能引起服务中断。我们的方案是建立一个临时的外表,生成临时的内表去替代线上表,这样速度是非常快的,因为整个Hologres做了线路的优化,效率非常高,直接去替代线上表,这样对线上几乎没有影响。
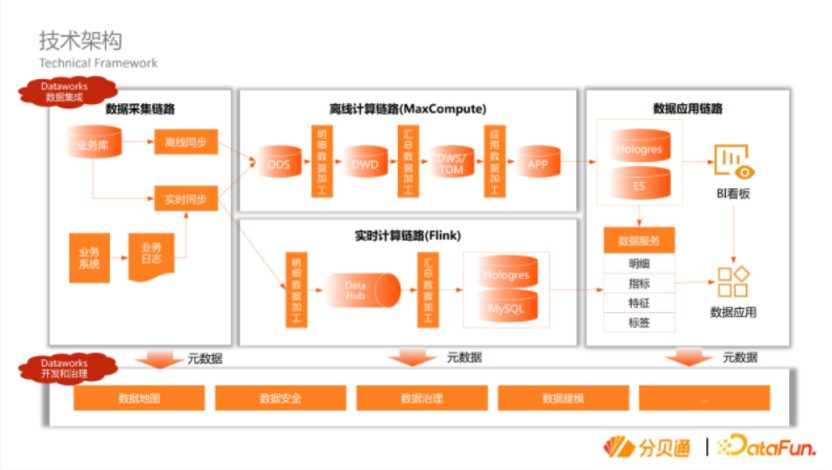
再来介绍一下算法方面的经验。先说一下Batch Mode的离线模型,我们目前使用的是阿里云的机器学习PAI来满足日常的建模场景,这个图是非常典型的数据流过程。首先样本经过实景化到ODS上面,在MaxCompute上进行清洗和加工,最后也会实景化到一些表,在模型训练阶段去开发、训练整个模型,训练完后有两种选择,一是不需要线上部署,只需要做一些离线的大表预测,可以通过Designer去做一些数据的部署数据湖到整个ODS的table里。第二是如果想做模型的线上服务,同样可以把模型输入到OSS层上面,通过EAS组件进行服务,这个是我们现在用的比较多的离线模型的数据流程。
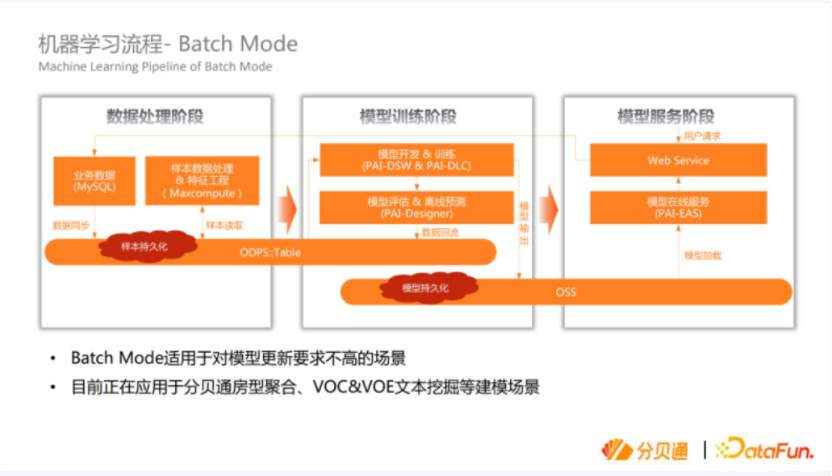
接下来是实时模型的流程,比如推荐等模型场景,对模型的实时性要求比较高。有一些比较通用的组件,比如Flink、kafka等进行数据的处理、特征的处理。模型的训练阶段先做一个模型的转化,离线的模型转化成实时的模型,然后进行训练评估,最后挂到线上去训练和替换,这里跟刚才的离线是不太一样的。
ToB企业与ToC企业的技术选型区别
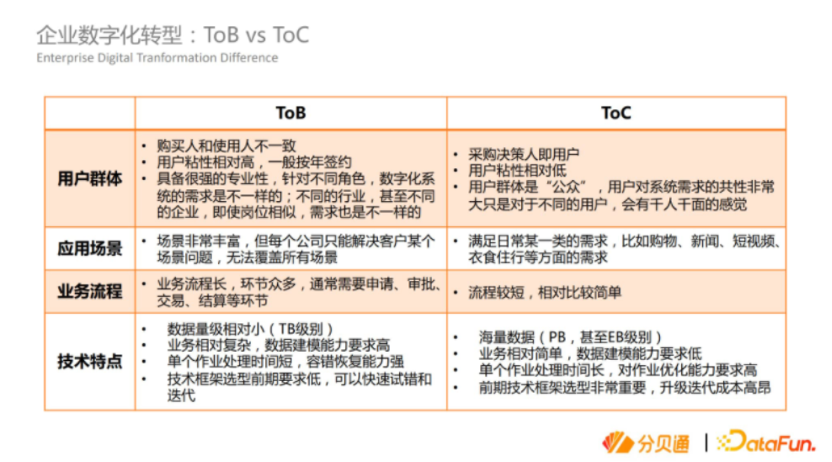
分贝通是典型的ToB企业。ToB和ToC企业存在一些差异,可以从三个方面来了解。首先是用户群体,对于ToB来说,购买决策和使用性都是不一样的,买一个软件可能是财务的决策、KP的决策,但是员工在用。ToB企业的用户粘性更高,一般按年签约,公司已购买员工必须使用,同时对用户有很强的专业性要求,针对不同的企业、角色,整个系统的设计是完全不同的,甚至相同行业相同岗位的需求也是完全不同的。ToC的采购决策者是个人,用户不满意可以放弃使用,粘性相对较低,用户群体相对公众化,用户对软件的需求有非常多的共性。
在应用场景方面,ToB的场景非常丰富,我们做的只能解决客户在生产过程当中某一个环节的问题,无法覆盖它所有方面的问题,因为专业性太强,一个问题的处理流程往往会很长,ToB在国内还没有千亿美金的互联网公司。ToC比较简单,满足大家日常生活中的需求,例如吃、穿、住、行、玩,很容易在这一领域诞生千亿美金的独角兽互联网公司,这决定了这两个企业的企业规模。
在业务流程方面, ToB领域业务流程都很长,通常申请审批交易结算等等,一次交易涉及到很多环节,但是ToC相对简单,例如网购下单仅需几秒钟,非常简单。
以上就是ToB和ToC企业的区别,也就决定了以下的技术特点,ToB的数据量相对较小,在做数字化转型的时候,包括我们自己,数据量还是TB级别,处于中小规模,但是业务相对复杂,对数仓的建模能力要求较高,需要了解业务后才能更好地去建模。整个作业的处理时间会比较短,我们现在的作业基本在分钟级别,因此我们的容错恢复很快,对于技术框架的选型要求会低一些,选错了后面还有翻盘的机会。但对于ToC来说,基础架构完全不一样,一旦选错了或版本需要升级,代价会非常高昂,这是在做数仓这两种模型的区别。

未来展望,可以分为两个方面,一个是业务方面,希望可以识别公司更多的数字化转型场景,我们希望通过产品化和平台化更好地帮助公司去做业务化、智能化的事情;同时推进业务的BP机制,推动业务的紧密合作,数据中台也要深入到业务中去,去了解业务内在的东西而不是等着业务提需求;现在更多的是报表类的支撑,希望未来发展为报告、智能化产品的支撑;虽然分贝通是企业支付的场景,但更多的是差旅方面,差旅是很复杂的过程,比如说出一次差,要做很多的决策,我们希望探索更加智能的用户体验,降低决策成本。
在技术层面,随着技术和数据的不断积累,对实时的数据要求越来越高,我们在实时与HTAP这块,会做一些深度的探索;现在的业务比较流行湖仓一体化,之前没有这种需求,现在我们需要管理语音、文本等大量数据,需要去解决非结构化数据储存和管理;第三是批流一体化,我们使用的是lambda架构,应用比较精简但是存在开发和运维上成本的重复,我们希望在这些方面继续探索来统一整个数仓,真正实现存储和数仓统一的架构,减少额外的成本,这将是我们未来探索的几个方向。
|