2023年6月28日消息,近日,猎豹移动CEO傅盛与金沙江创投董事总经理朱啸虎在朋友圈“吵”起来了。事情起因是傅盛转发了一篇朱啸虎否定大模型创业的相关文章,并配文“硅谷一半的创业企业都围绕ChatGPT开始了,我们的投资人还能这么无知者无畏。”
随后,朱啸虎本人下场评论区“反击”,“99%的价值都是GPT创造的,这样的创业公司有什么价值”。
傅盛随即回复说,“互联网99%的规范都是 tcpip创造的,创业有价值吗?汽车99%的价值都是热力学定义创造的,创业有价值吗?大多数中小网站的流量都是搜索引擎带来的,那创业有价值吗?”
朱啸虎认为,傅盛这样说是在“抬杠”。随后两人来回激辩多次,核心争论点在“中国创业者到底该不该逐鹿大模型,能创造什么价值”。
两位大佬为大模型展开的激辩,引发热议。微博认证为“杜克大学电子与计算机工程系教授,计算进化智能中心主任,美国NSF下一代移动网络与边缘计算人工智能研究院主任”的网友@陈怡然-杜克大学也忍不住下场评论了。
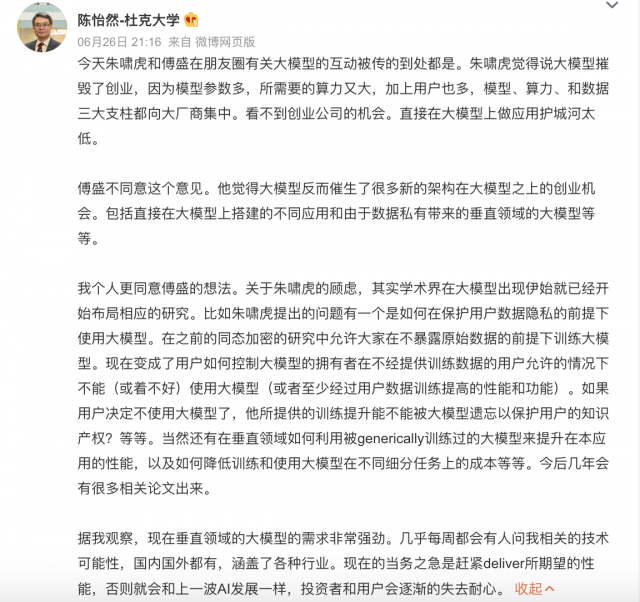
@陈怡然-杜克大学总结了傅盛和朱啸虎的核心观点。朱啸虎觉得大模型摧毁了创业,因为模型参数多,所需要的算力又大,加上用户也多,模型、算力、和数据三大支柱都向大厂商集中。看不到创业公司的机会。直接在大模型上做应用护城河太低。
傅盛不同意这个观点。他觉得大模型反而催生了很多新的架构在大模型之上的创业机会。包括直接在大模型上搭建的不同应用和由于数据私有带来的垂直领域的大模型等等。
@陈怡然-杜克大学说,“我个人更同意傅盛的想法。关于朱啸虎的顾虑,其实学术界在大模型出现伊始就已经开始布局相应的研究。比如朱啸虎提出的问题有一个是如何在保护用户数据隐私的前提下使用大模型。在之前的同态加密的研究中允许大家在不暴露原始数据的前提下训练大模型。现在变成了用户如何控制大模型的拥有者在不经提供训练数据的用户允许的情况下不能(或着不好)使用大模型(或者至少经过用户数据训练提高的性能和功能)。如果用户决定不使用大模型了,他所提供的训练提升能不能被大模型遗忘以保护用户的知识产权?等等。当然还有在垂直领域如何利用被generically训练过的大模型来提升在本应用的性能,以及如何降低训练和使用大模型在不同细分任务上的成本等等。今后几年会有很多相关论文出来。”
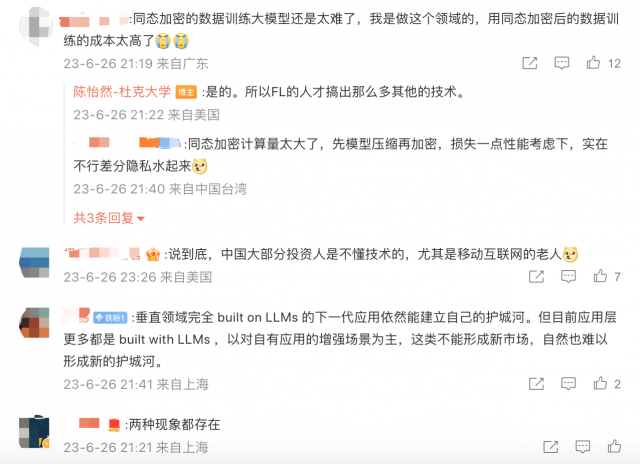
不过,也有从业者表示,“同态加密的数据训练大模型还是太难了,用同态加密后的数据训练的成本太高了。”
或许是没想到与傅盛的“互怼”会引发这么大的关注,朱啸虎又发了朋友圈解释了一番。
他表示,“昨天的对话造成很多误解,其实我们应该是国内垂直AIGC真正出手最多的早期投资人(这句话在对话中被故意删掉了)。核心观点:不要迷信通用大模型。”
“明年3.5就成 commodity,3年后4也将是commodity!对于大部分创业者,场景优先,数据为王!”朱啸虎称。
@陈怡然-杜克大学也表示,“现在垂直领域的大模型的需求非常强劲。几乎每周都会有人问我相关的技术可能性,国内国外都有,涵盖了各种行业。现在的当务之急是赶紧deliver所期望的性能,否则就会和上一波AI发展一样,投资者和用户会逐渐的失去耐心。”
据了解,自从ChatGPT掀起大模型热潮,如何将大模型能力应用到自身的行业和场景里,以及解决成本、数据、安全等大模型实际落地难题,已经成为行业关注的焦点。
此前,百度、阿里等大厂已经官宣伙伴计划和工具链,声称要让每一个行业都能够用上自己的大模型。腾讯也在上周公布了行业大模型的最新研发进展,为10余个行业提供了超过50个大模型行业解决方案。
与此同时,很多创业企业也马力全开,金融、教育、医疗、自动驾驶等多个垂直领域的公司都已相继传出要推行业大模型的消息。大模型的战事,已经开始从通用大模型卷向更加垂直的行业大模型。
但就目前来看,行业大模型大多其实都还停留在讲概念、讲技术、进行内部测试或项目定制的阶段,在具体落地和商业化层面尚未实现质的突破。巨头入局后,会带来哪些令人惊喜的落地产品或应用,值得期待。